
前面文章討論很多關於可觀測性的觀念與工具,最重要的是在實務面上我們如何將理論實際應用,來解決真實世界上開發團隊所遇到的問題
透過可觀測性,我們如何具體幫助線上問題釐清呢?
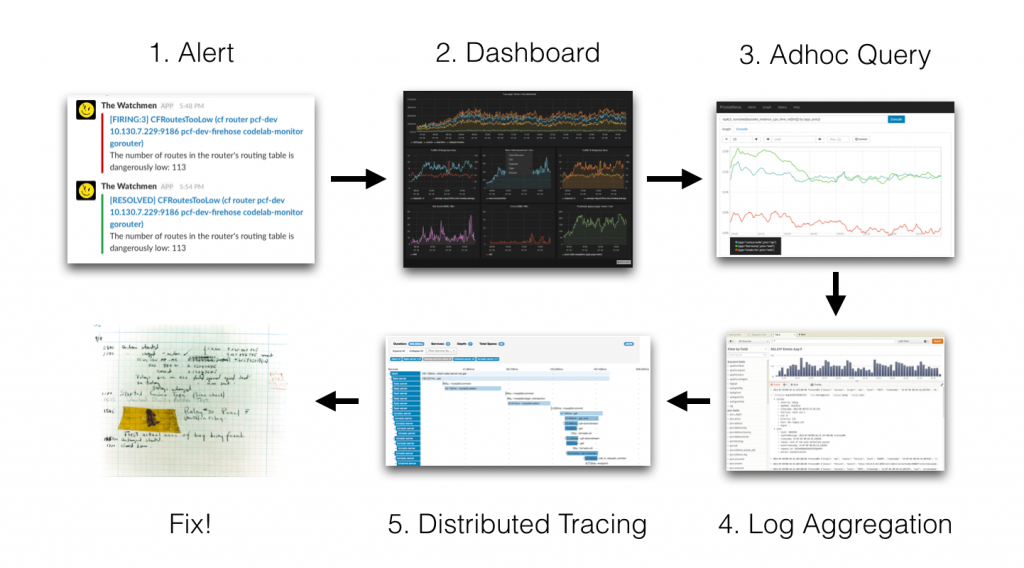
如果你是開發或是運維團隊人員,當線上系統或負責應用程式遇到問題時,會做哪些事情來協助定位問題,上圖是當問題發生到被修復可能的流程
透過上述的流程與步驟之後了解到每個步驟的細節,接著整理各個步驟其主要目的如下
| 步驟 | 核心目的 | 目的 |
|---|---|---|
| 警報 (Alert) | When | 立即通知團隊,讓他們迅速回應問題 |
| 儀表板 (Dashboard) | What | 即時視覺化系統狀態,助於定位問題 |
| 查詢 (Adhoc Query) | How | 深入探索數據,查詢特定的數據點或時間範圍。 |
| 日誌 (Log Aggregation) | Where | 提供應用或系統的詳細日誌 |
| 分布式追踪 (Distributed Tracing) | Why | 在分散式系統架構中,請求如何在多個服務之間流動,找到可能的瓶頸 |
| 修復 (Fix!) | Action | 一旦問題被確定,立即採取措施來解決它,如代碼修復、配置調整或服務重啟。 |
以上流程可以看到可觀測性中強調的信號 metics、logging、trace 在問題定位上扮演重要的角色,可以幫助問題發生當下縮短系統異常的恢復時間 (MTTR),也可以看出前面文章提到的監控與可觀測性是相符相乘的,無法取代彼此。
Grafana 生態系提供了一系列強大的工具,可以輔助開發團隊預防、定位及後續的分析跟優化,以下是針對各階段的工具說明
事前預防
事中處理
事後分析

透過事前預防、事中處理與事後分析,加上結合 Grafana 可觀測性的工具,可以更有效的處理管理與加速問題處理速度。但實務面上除了工具的使用之外,更重要的是 團隊成員的合作 與 清晰的 SOP 機制 也不能忽視。
不同人代表有各種不同的工作方式與思維。舉例來說在寫程式時 Junior 與資深的開發人員對於程式寫法不同,為了確保程式的可讀性,就會需要定義制定統一規範並在 Code Review 落實,才有機會大家在看 Code 跟閱讀時更加輕鬆。
同理,在緊急問題處理時需要定義清楚異常事件的 SOP,以便問題發生時知道該採取哪一些步驟,包含該使用那些工具分析與定位、定時回報的機制事後事故報告(RCA)內容寫法,減少混亂並確保團隊成員都可以依照相同方式進行操作,在新成員加入時也不會因為認知落差而影響到處理時效性,提高其處理問題的效率。
補充:在處理線上問題時,核心目的是先止血,不是急於尋找根本原因。這也是為什麼我們需要清晰的流程和工具來協助我們在問題發生時快速應對,而不是盲目地尋找問題的原因 (思路 : 止血、暫時解、根本解)。
下一篇將介紹 Grafana 提供 Grafana Incident Response & Management (IRM) 解決方案,如果有任何疑問或想法,歡迎留言提出討論 !
Beyond the 3 Pillars of Observability

